


出品 | 搜狐科技
作者 | 梁昌均
编辑 | 杨锦
刚刚过去的周末,300多台机器人跑上马拉松赛道。夺冠的机器人用时不仅比上次缩减了一半多,还打破了人类半马的成绩。
这背后是人形机器人运动控制、动力效率、系统稳定等综合能力的进步。但此次参赛的六成选手依然是遥控机器人,而自主导航的机器人也出现失控、摔倒等问题。
“这次比赛很大程度上依然是硬件和小脑系统层面的比拼,但行业发展焦点已经是大脑层面,这次并没有体现出太多进步。”有机器人从业者表示。
这显示出具身模型——机器人大脑发展的相对滞后。而对这个爆火了一年多的行业来说,数据依然是具身模型发展的最大瓶颈,行业也还没有找到有效解法。
这吸引了不少玩家入局,除了智元等初创企业,不少大厂也从中看到了机会,行业由此形成明显的技术路线分歧。
近日,京东继宣布以建成全球最大具身数据采集中心为目标的“女娲计划”后,又推出覆盖全链路的具身智能数据基础设施,持续加码具身智能赛道。
除了京东,百度、阿里、字节、腾讯等也在布局。它们一手通过投资,一手通过搭建数据平台或研发具身模型,试图在这波具身智能热潮中抢占生态位。
数据瓶颈有多大?
自去年以来,具身智能就成为AI领域最火爆的领域之一。无论是投资规模,还是企业数量,都在快速增长。
然而,从业者却感觉到,具身智能尤其是模型层面的进步,还未出现大的跃迁。要想让机器人摆脱人为遥控,走向一定程度的自主智能,挑战不少。
“整个具身领域发展到今天还是一个非常早期的阶段,现在碰到最大的问题是数据短缺,导致具身模型没有办法训练出来。”
数据是模型的燃料。但不同于大语言模型天然就有丰富多样的公开语料供其训练,具身数据则处于原始匮乏的状态。
智元机器人联创姚卯青就透露,GPT-5训练语料折合约100亿小时,而全行业的具身数据仅约50万小时。
京东高管也在近日的京东具身智能生态发布会上告诉搜狐科技,现在市场上的具身数据集还在几十万小时的体量,而要想训练出真正好的、具备泛化性的具身模型,至少需要一千万小时量级的数据。
如何解决数据问题,企业各显神通。智元为此成立了专门的数据采集公司觅蜂科技,计划在2026年实现千万小时级数据产能,到2030年实现百亿小时级数据产能。
全国也掀起了具身智能数采中心建设热潮,北京人形机器人创新中心和上海的国家地方共建人形机器人创新中心均打造了专业化的数据采集基地,并牵头制定行业标准,推动开源开放。
这还催生了专门的数据采集服务公司,除智元成立的觅蜂科技,还诞生了光轮智能、灵生科技等创业公司。
京东的“女娲计划”也正是为了解决具身数据瓶颈。
该计划将发动超60万人,聚焦京东供应链场景,两年内积累1000万小时人类真实场景视频数据,京东号称这将是“人类历史上规模最大的数据采集行动”。
此外,京东还推出自研的数采设备,以及数据加工处理平台、具身大模型和具身智能数据交易平台,形成覆盖采、存、标、训、评、仿、测、用全链路的具身数据产业链。
看上具身数据这门生意的大厂不止京东,百度也在入场。百度智能云此前联合多家具身智能企业,推出具身智能数据超市,以解决行业数据标准不一、流通不畅的痛点。
对比来看,其它大厂包括阿里、腾讯、字节等,则在底层的数据采集层面动作不多,而更多是在数据处理、训练评估、仿真测试等方面提供基建服务。
某种程度看,谁掌握了更多更好的数据,谁就有可能在具身模型上率先取得突破,具身智能行业将围绕数据打响争夺战。
具身数据生意经不好念
面对具身智能的数据荒,多方都想进入淘金,但这门生意经并不好念。规模、成本、质量、能否跨本体,都是挑战。
搜狐科技从多位业内人士了解到,目前具身数据存在着明显的数字金字塔结构。
最底层是互联网公开数据,量大管饱,但对具身模型来说,缺乏指向性和具体场景,往往只能用来做基础能力的预训练,让模型学习通用世界知识和语言理解。
再往上则是人类实操的第一视角数据以及虚拟环境中生成的仿真合成数据,站在塔尖的则是机器人本体视角数据,典型如真机遥操数据。
从下往上,越难获取,价值越高,采集成本也越高。
多数观点认为,真机遥操很难实现数据的规模化,场景的多样性不足,采集成本也非常贵,而且大部分没有在真实场景进行,所以会极大制约具身智能模型训练的Scaling Up。
姚卯青就透露,目前国内真机数据的市场价格在每小时500-1000元之间,而无本体数据的价格预计收敛至真机数据的三分之一到二分之一。
“过去具身数据大部分都是做机器人遥操,很多头部公司也就两三万条的遥操数据。如果坚持遥操的话,会发现场景非常受限,很多场景无法覆盖,智能化程度就会受到很大的制约。”
京东具身智能业务有关负责人表示,京东采用的是人类第一视角的数据来解决具身模型训练的Scaling Up问题,也就是通过人佩戴设备在各种场景去采集视频数据。
同时,具身模型的训练对数据质量的要求也非常高,如果数据质量不行,难以实现较好的训练模型的效果。
这则涉及到数据采集设备是否足够稳定,算法是否足够精准,以及采集过程中是否有一定的质量控制,包括后续数据的质检、过滤等,都会影响到最终的数据质量。
“一定要用高质量的数据集,想降成本也不能降低数据的质量,否则所谓的降成本就没有任何价值。”京东前述负责人强调。
同时,目前具身数据还存在割裂问题,如真机遥操对本体的依赖和限制,导致无法做跨本体的迁移和操作等。这也形成了多样的技术路线,如仿真派、真机派的分歧还在延续。
帕西尼创始人许晋诚则认为,具身数据的采集范式将从遥操、仿真时代逐渐走向以人为中心的人机解耦时代和EGO(第一视角)时代,未来则会迈向EGO+触觉的全模态时代。
有具身模型研发人士告诉搜狐科技,目前具身智能远没有到Scaling Up非常强的地步,随着数据量级的扩充,具身模型泛化能力还在指数级别提升。
这也是目前业内更关注数据的原因。同时,业内也在探索VLA、WAM、世界模型等各种模型架构。“但离真正的应用落地都还有很远距离,谁会成为主流,现在无法给出定论。”
该人士还认为,具身数据的问题,并非靠哪家企业就能完全解决。
哪怕是京东,也在呼吁希望更多的行业伙伴加入,而不是靠自己单打独斗。“我们做这件事情并不是单纯要做数据服务的提供商,更多还是希望能建立针对具身行业的生态联盟。”
因此,想要彻底解决数据瓶颈,需要行业共建,形成开源开放的生态。
大厂抢注AI下一个风口
纵然数据的问题依然悬而未决,但今年以来,随着多家机器人走上春晚,具身智能这波热潮依然还没有退去的势头,机器人马拉松则让这波热潮持续。
更显著的趋势是,行业融资在疯狂加速。
据IT桔子,今年以来机器人板块披露金额的122起融资中,资金总规模约345亿元,而去年融资总额为588亿元。这相当于不到四个月,就完成了去年行业近六成的融资。
同时,大额融资频频出现,今年单笔10亿元及以上的融资至少已有15起,多家企业轮番刷新单笔融资纪录。最新纪录由它石智航创造,Pre-A轮获得4.55亿美金融资。
这也由此快速催生了一批估值超百亿的具身智能独角兽。
搜狐科技不完全统计,国内目前有宇树、智元、众擎、自变量、星海图、云深处、智平方、帕西尼、银河通用、千寻智能、星动纪元、逐际动力、灵心巧手、极佳视界、它石智航等至少15家具身智能公司的估值超过百亿。
这其中,宇树科创板上市申请已获得受理,多家企业完成股改。可以预见,未来一两年内,具身智能赛道有望迎来上市潮。
这些融资背后站着诸多大厂,百度、阿里、蚂蚁、腾讯、京东、美团等相对积极,至少都出手五次以上。
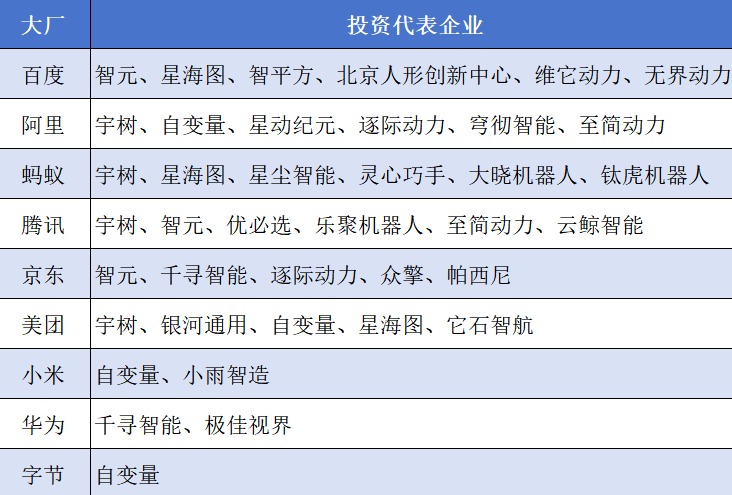
宇树、智元、自变量、星海图等同时获得多家大厂加持。宇树同时获得阿里、蚂蚁、腾讯、美团四家大厂投资,自变量则同时获得字节、阿里、美团、小米四家大厂投资。
具身智能被视为AI的下一个风口,是物理AI的核心赛道,不少机构都预测其有着万亿规模的市场潜力。
值得注意的是,除了投资,不少大厂自身还在围绕具身数据、具身模型和基础设施方面进行布局,以此想要成为具身行业的基建。
Omdia发布的《中国具身智能AI云市场1H25》显示,百度智能云、阿里云、腾讯云、火山引擎、华为云等是该市场的主要玩家。随着京东的发力,市场格局或会发生变化。
小米还在自研机器人本体,阿里旗下的高德则在探索四足机器人,而华为、腾讯、百度和蚂蚁等此前均表态不会做机器人,而是专注模型基座或基础设施服务。
一手做投资、一手搞基建,大厂在这波具身智能热潮中,可以说相当积极。这背后不仅仅是短期的生意,更是大厂对AI下一个风口的提前押注。返回搜狐,查看更多





 关注网站
关注网站